FIND THE RIGHT SOLUTION FOR YOUR BUSINESS
Software Development In Toronto
Basic software systems are no longer capable of keeping up with the always-changing business needs. That’s why the key feature of custom software is its flexibility and the ability to scale with the business. We at Vestra Inet, a Toronto-based custom software company, offer custom solutions that are fully tailored to your business with an emphasis on scalability, functionality and user experience.
From inventory control, production and finance management to enhanced inter-department communications and real-time reporting, everything can be addressed by one custom software development company, with one integrated system. Browse the list of solutions we have built in the past and book a consultation to learn how custom software can become a breakthrough moment in your business.
























TARGET CUSTOMERS WITH UNIQUE UX DESIGNS
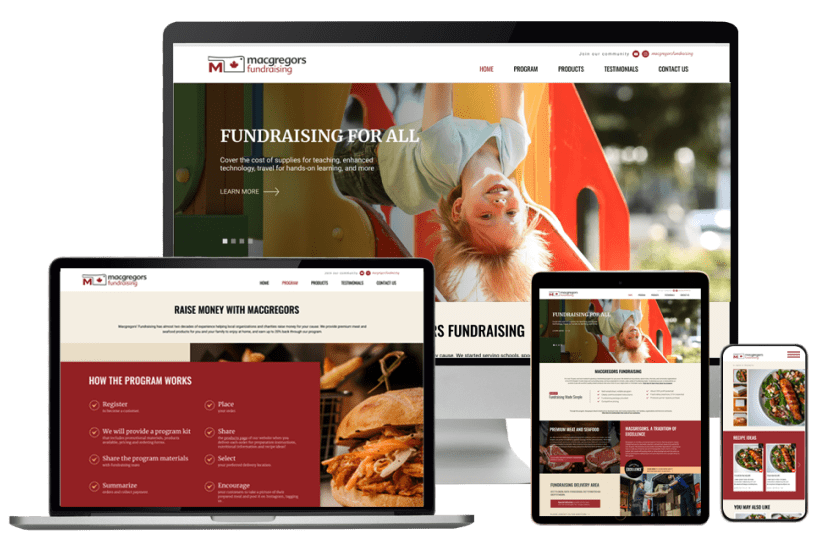
Website Design
We are not just a software development company; for many years, our core expertise has been industrial and commercial custom website design. We at Vestra Inet know that the key to your success is a functional website built with your target audience in mind. That’s why we don’t just build the website for you – we also build it for your customers. Our goal is to make user-friendly, highly functional and visually appealing websites that will attract visitors and turn them into customers.


LET POTENTIAL CUSTOMERS FIND YOU
We have been doing online marketing in Toronto for over 10 years and have accumulated the knowledge, experience, and resources necessary to ensure your campaigns are successful and results are quick. Brand exposure begins with SEO and a strong online marketing campaign tailored to promote your key products and services. We get your website localized and on the map so that search engine maps prioritize your appearance. Your business will funnel in visits from everyone in your area by utilizing local online promotion techniques. This will help you reach clients close to your business, which will help you grow your network and get more business faster. Add to this custom software development and your company will be ready to handle more clients faster.



















